Intuition
Our key idea is to explicitly model negative examples based on our prior knowledge. Intuitively, one effective way to explain the social norms behind positive examples is to portray the opposite negative examples like collisions. Our method can be viewed as a form of negative data augmentation through self-supervision, as opposed to laboriously collecting additional state-action pairs from dangerous scenarios.

Above is an illustration of different learning approaches to sequential predictions:
Method
We formulate this intuition into a new learning framework that consists of two components, a social contrastive loss and a negative sampling strategy.

Given a scenario that contains a primary agent of interest (blue) and multiple neighboring agents in the vicinity (gray), our Social-NCE loss encourages the extracted motion representation, in an embedding space, to be close to a positive future event and apart from some synthetic negative events that could have caused collisions or discomforts.
Trajectory Forecasting
Our method tends to jointly adjust the trajectories of multiple agents, whereas the vanilla method leads to collisions between the primary (black) and the nearby agent (red).
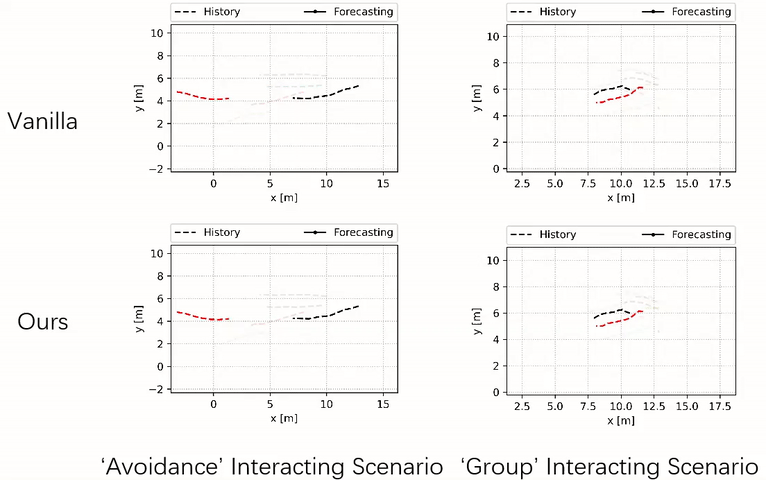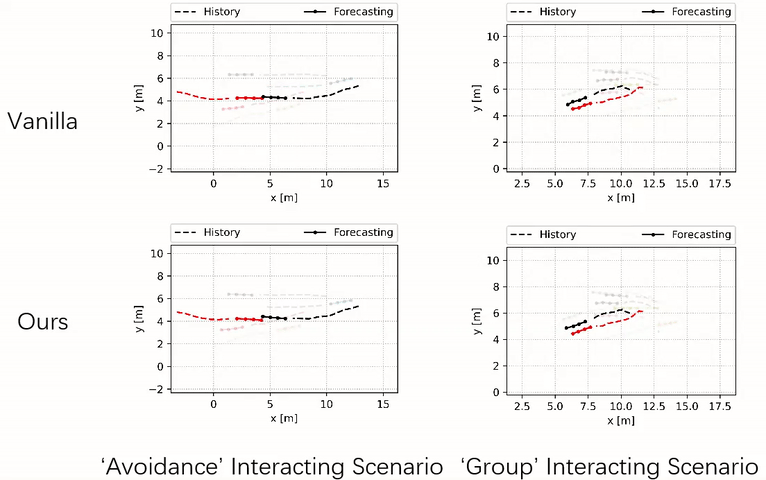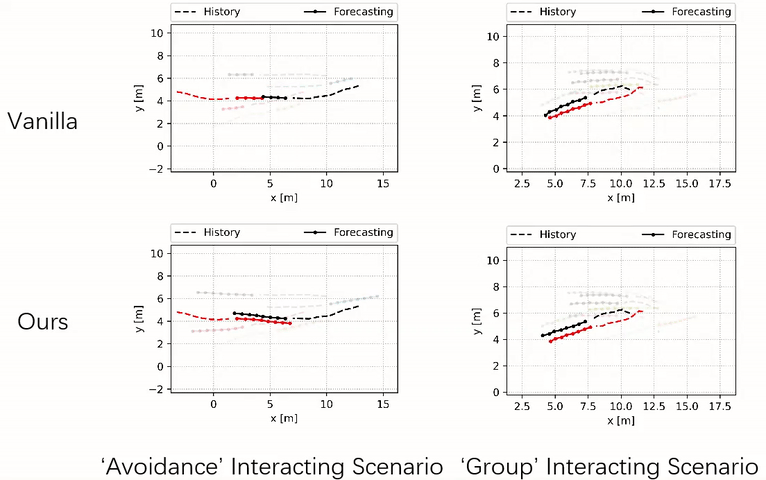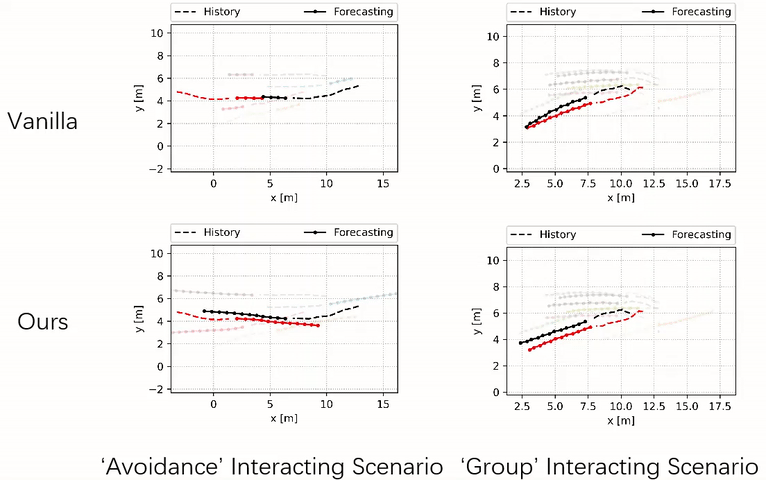
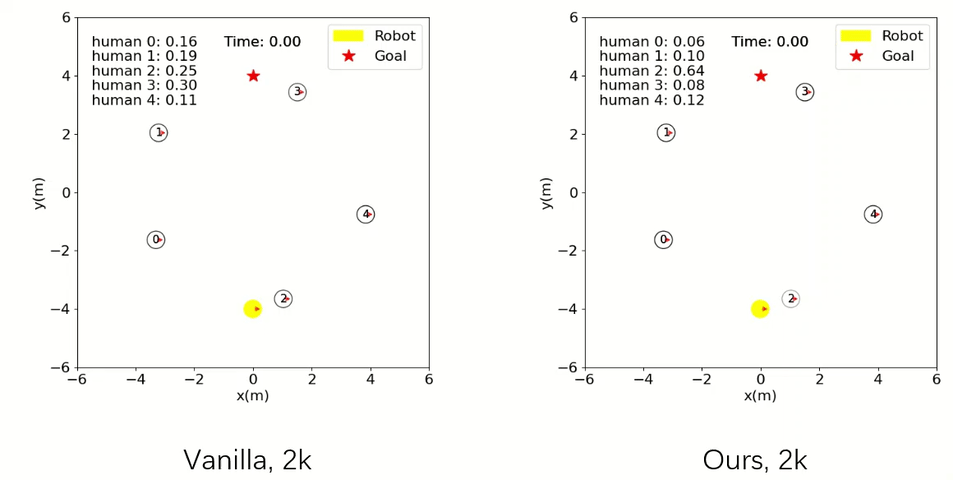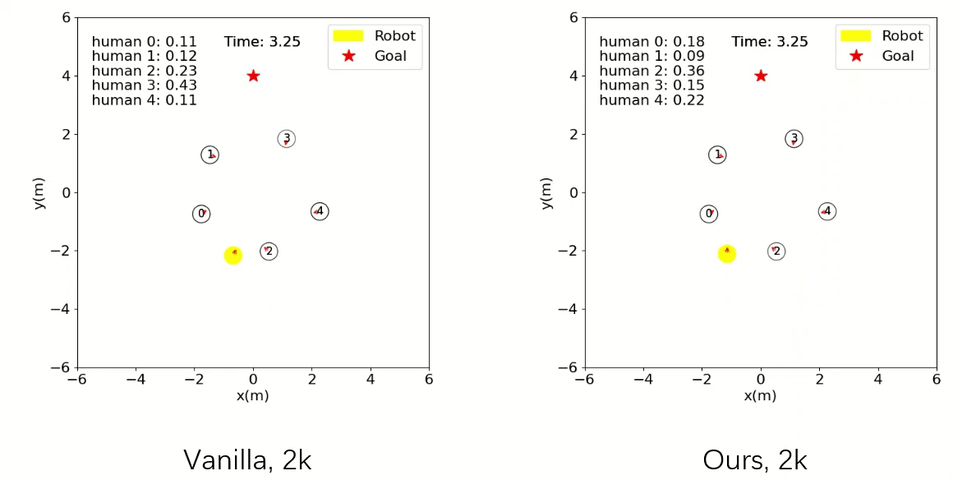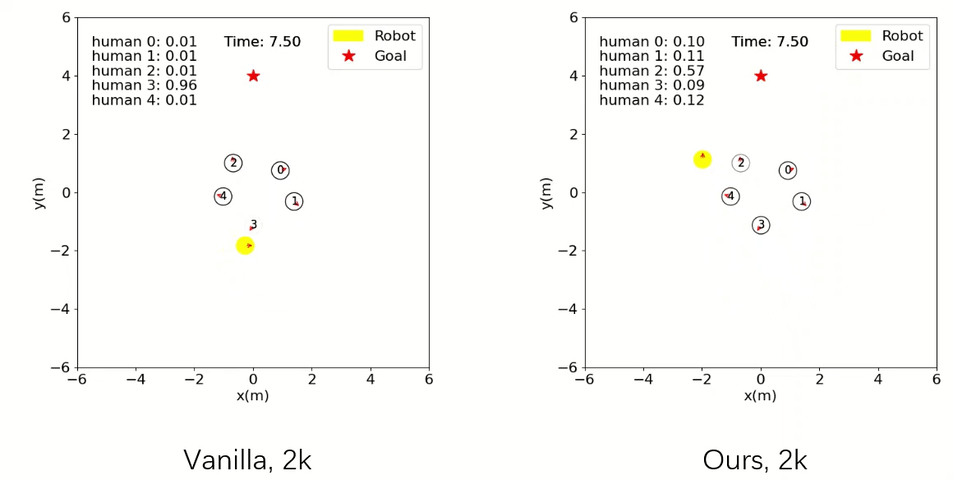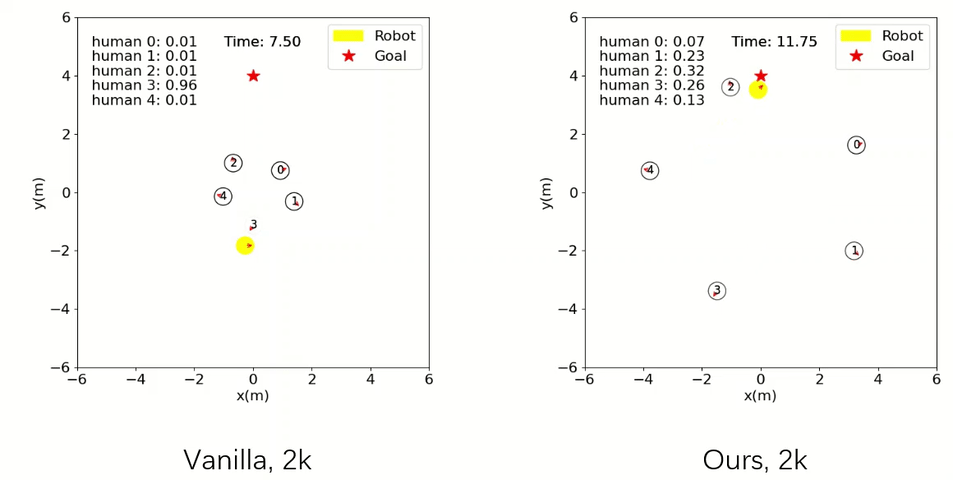
Robot Navigation
The agent trained with our method is already able to accomplish the navigation task safely and efficiently, whereas the baseline one crashes with collisions.